

- 入门教程
- 查询告警和关联 Graph 图表
入门教程
查询告警和关联 Graph 图表
xObserve 没有提供告警配置的功能,因为我们认为:专业的事情交给专业的人做。
如果你使用的是 Prometheus,你可以在 Prometheus 中配置告警规则,如果你使用的是其他 APM 服务,你也可以在这些服务中配置告警规则。
xObserve 主要负责告警展示:
- 在告警页面或者告警图表中查看告警
- 将告警关联到 Graph 图表中展示
它们各有各的用途,下面分别来看看。
告警仪表盘
在 xObserve 中有两个特殊的仪表盘,它们都拥有自己特殊的 id:
- Home 仪表盘:
d-home - Alert 仪表盘:
d-alert
它们都是在 Data 初始化时自动创建的,无法被删除,也无法修改 id (当然,其它 dashboard 也不能修改 id)。
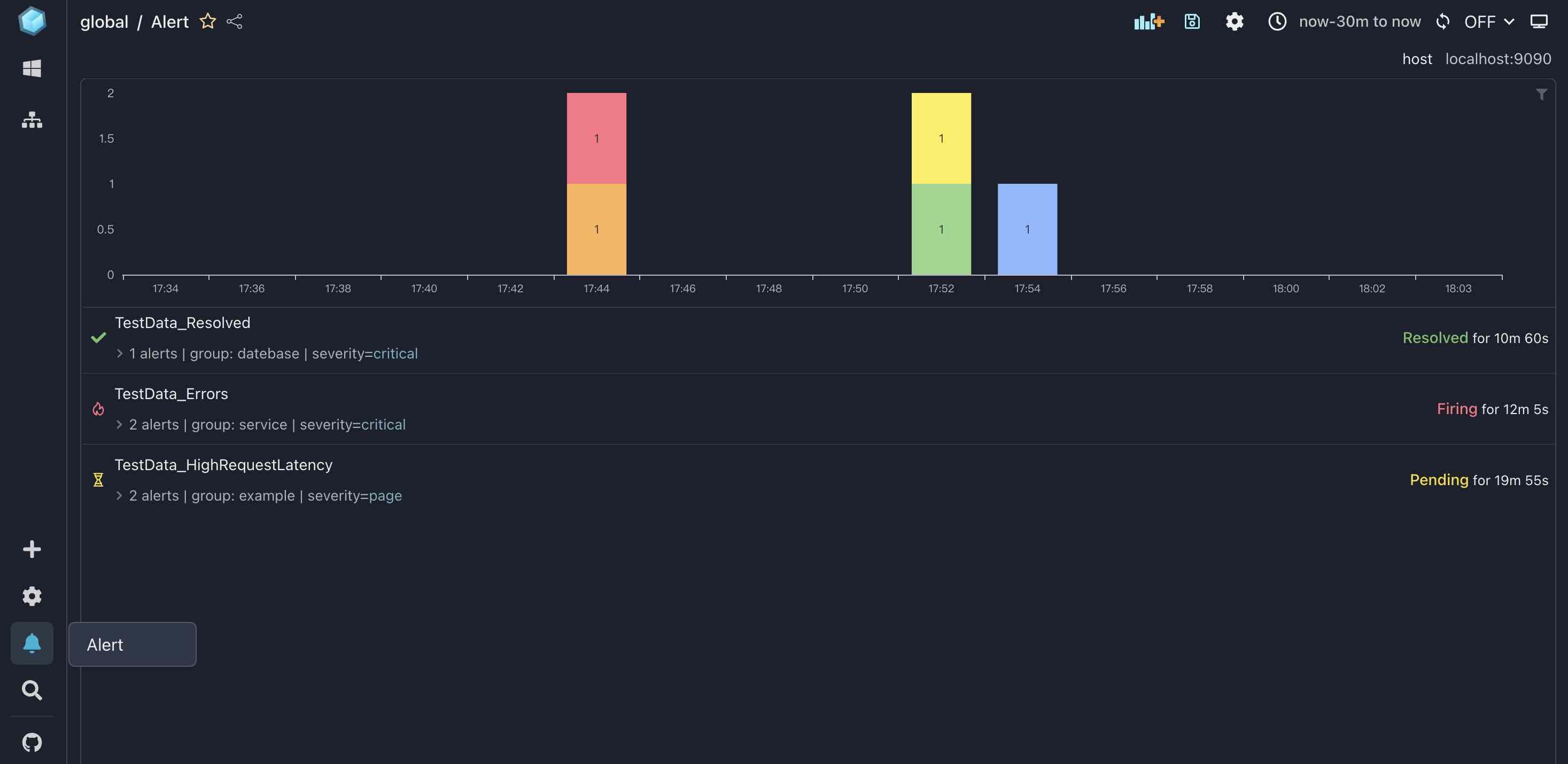
特别的,Alert 仪表盘还有一个预定义的 url 路径: /alert。你可以点击侧边导航栏中的告警图标,或者直接访问 http://localhost:5173/alert 来访问告警仪表盘。
假设你已经访问了告警页面,那么你应该会看到一堆告警。 你可能会想:为什么这里有这么多告警?我并没有在 xObserve 中创建告警。答案很简单:这些告警都来自 TestData 数据源。
在 Prometheus 中添加告警规则
对于想看到告警长啥样,TestData 很有用,如果你想要展示真实的告警,它直等于没用。由于 Prometheus 是 xObserve 的核心数据源,所以我们将使用它来展示如何在 xObserve 中添加告警。
首先,让我们在 Prometheus 中创建一些告警规则。
目前,我们只能通过 Prometheus 的配置文件来创建告警规则,官方没有计划通过 web api 来配置它 :( 但是不用担心,这种方式很容易使用,并且与 web api 相比,通过配置文件配置告警还可以减少很多不必要的告警规则,懂得都懂。。
在 Prometheus 安装目录中找到 promtheus.yml 配置文件(也许你有其他配置文件名或安装路径),并添加如下内容:
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- "first_rules.yml"
# - "second_rules.yml"在该配置文件中,只需要定义告警规则所在的文件名,具体的告警规则定义在 first_rules.yml 中。
接着在 prometheus.yml 的同级目录中,创建一个新的文件:first_rules.yml, 并写入如下内容:
groups:
- name: example
rules:
- alert: HighRequestLatency
expr: go_gc_duration_seconds_count > 20
for: 2m
labels:
severity: page
annotations:
summary: High request latency可以看出,这个告警规则毫无意义: 当 go_gc_duration_seconds_count 的值大于 20 并持续超过 2 分钟就进行告警。
说它毫无意义,是因为在 Prometheus 启动一小段时候后,这个语句的值肯定是妥妥的大于 20 的,可以说是 100% 能触发告警。
但是话说回来,我们想要的不就是这样一个必定触发告警的规则吗?不然你如何快速观察到告警数据 :)
总之,在配置后,重新启动 Prometheus 服务器,然后回到我们的 xObserve UI。
获取更多关于告警配置的信息,请访问 Prometheus 官网。还是那句话, xObserve 并不依赖于 Prometheus, 我们只是查询数据。 至于告警的配置和发送,这都是 Prometheus 完成的。
从 Prometheus 查询告警
由于我们之前已经设置了 Prometheus 数据源,因此只需:
- 访问 /alert 页面,打开它的图表编辑面板
- 在
图表的标签页下找到告警过滤
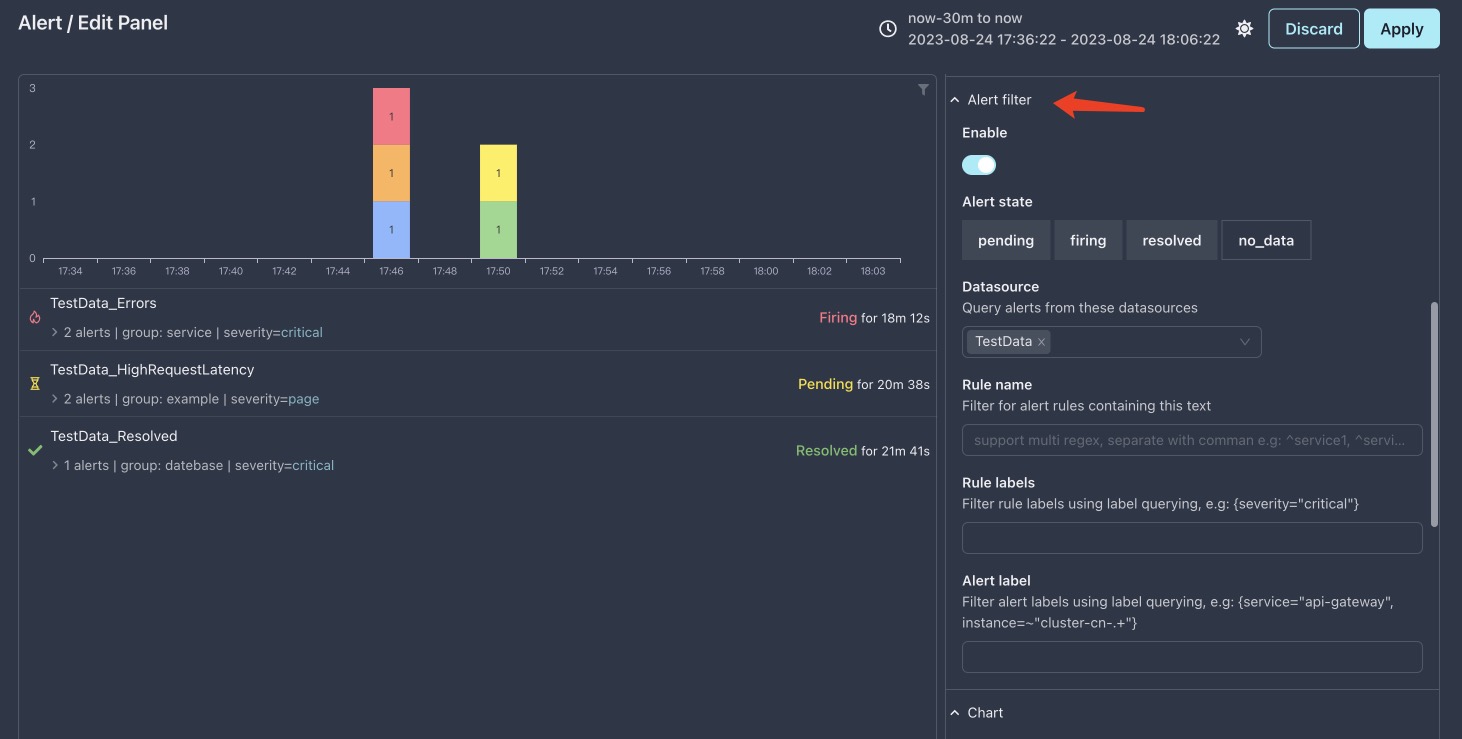
- 在
数据源中选择prometheus,并且移除TestData,注意这里可以多选
如下图所示:
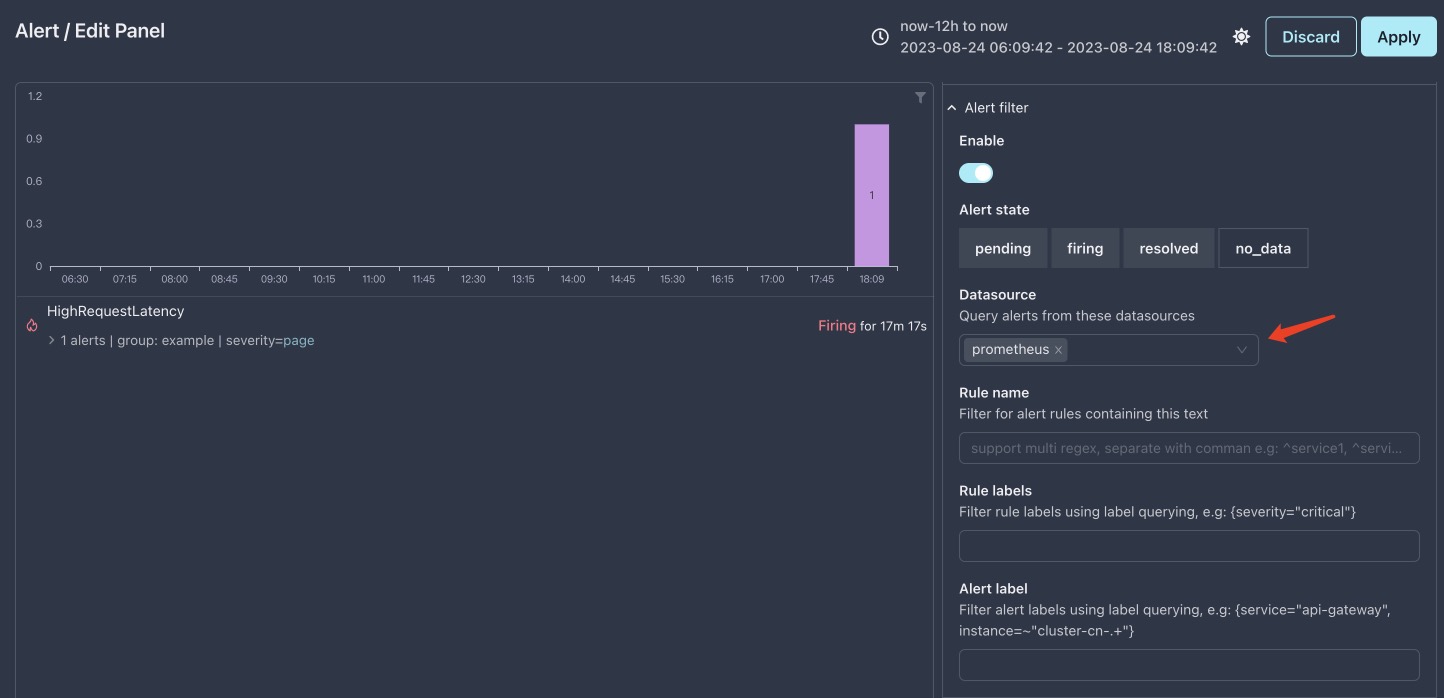
此时,我们已经从 Prometheus 中查询到真实的告警,下面来深入了解一下这个告警规则。
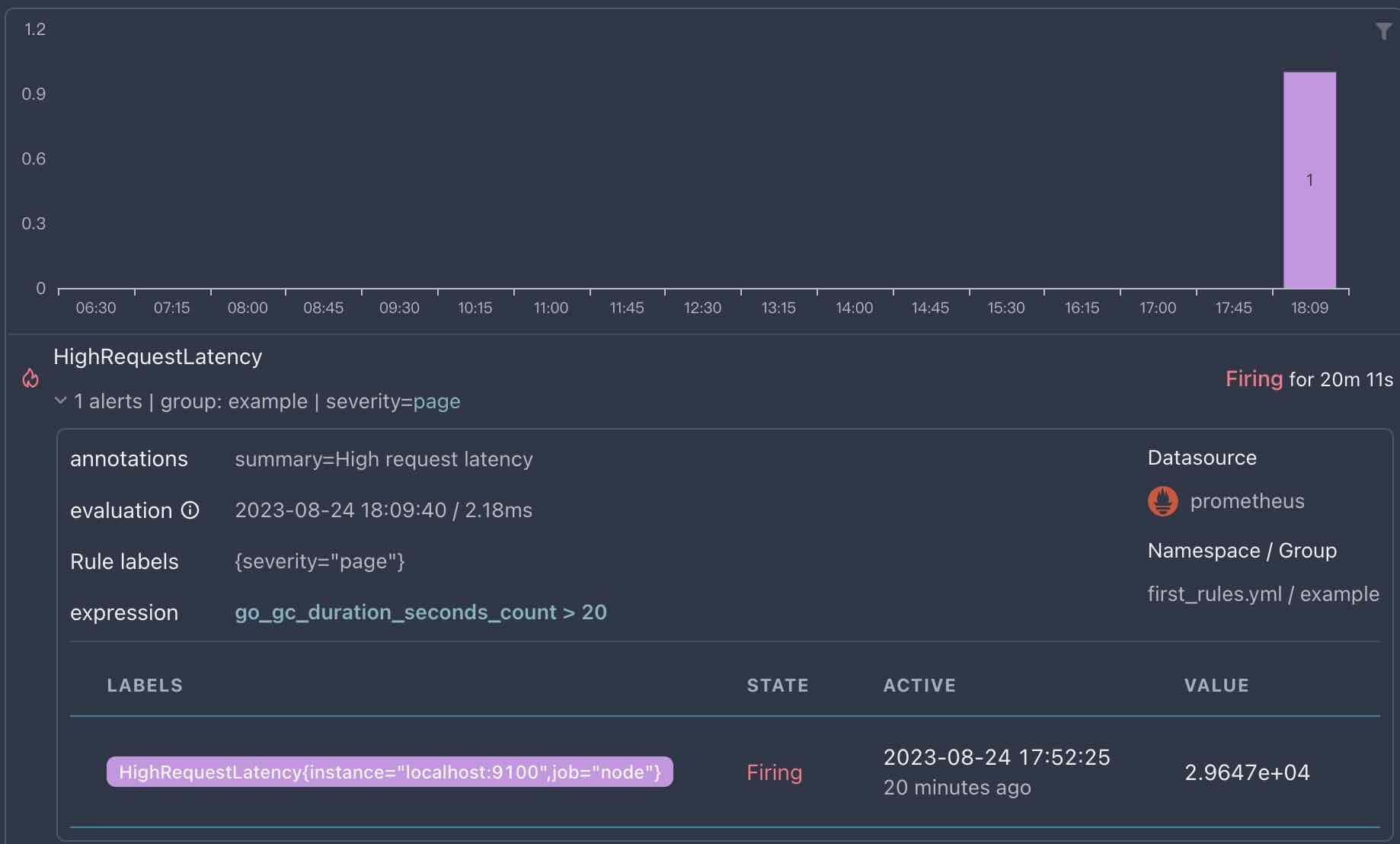
可以看到,告警规则的定义与 Prometheus 中的定义完全一致,因为 xObserve 原生支持 Prometheus 的告警规则展示,而无需任何转换。
如果你通过 HTTP API 加载其它系统的告警列表,那么你需要将其转换为 xObserve 的告警格式,然后才能展示出来
何时使用
告警页面是一个通用的告警展示页面,当你想要查看系统中发生的所有告警,并且想要自由探索它们时,你可以访问 /alert 页面。
将告警关联到 Graph 图表
除了在告警页面查看告警外,你还可以将告警关联到 Graph 图表中,这样可以更直观的看到告警发生的时间点和状态。
让我们在 Home 仪表盘中创建一个 Graph 图表用于告警关联,因为告警图表通常放在首页的仪表盘中。
选择 global 团队的侧边导航栏
在侧边导航栏的底部,点击 用户 图标,然后将鼠标悬停在 选择侧边导航栏 上,选择 global 团队的侧边导航栏。
当侧边导航栏切换后,你应该会看到侧边导航栏顶部出现了 Home 仪表盘。
创建 Graph 图表
此时,那个欢迎图表对我们来说已经没有用了,我们将其替换为一个 Graph 图表。
- 打开欢迎图表的编辑面板
- 将类型修改为
Graph - 将数据源修改为
prometheus,并选择go_gc_duration_seconds_count指标,因为我们的告警规则就是基于该指标的。
此时你将看到如下的图表:
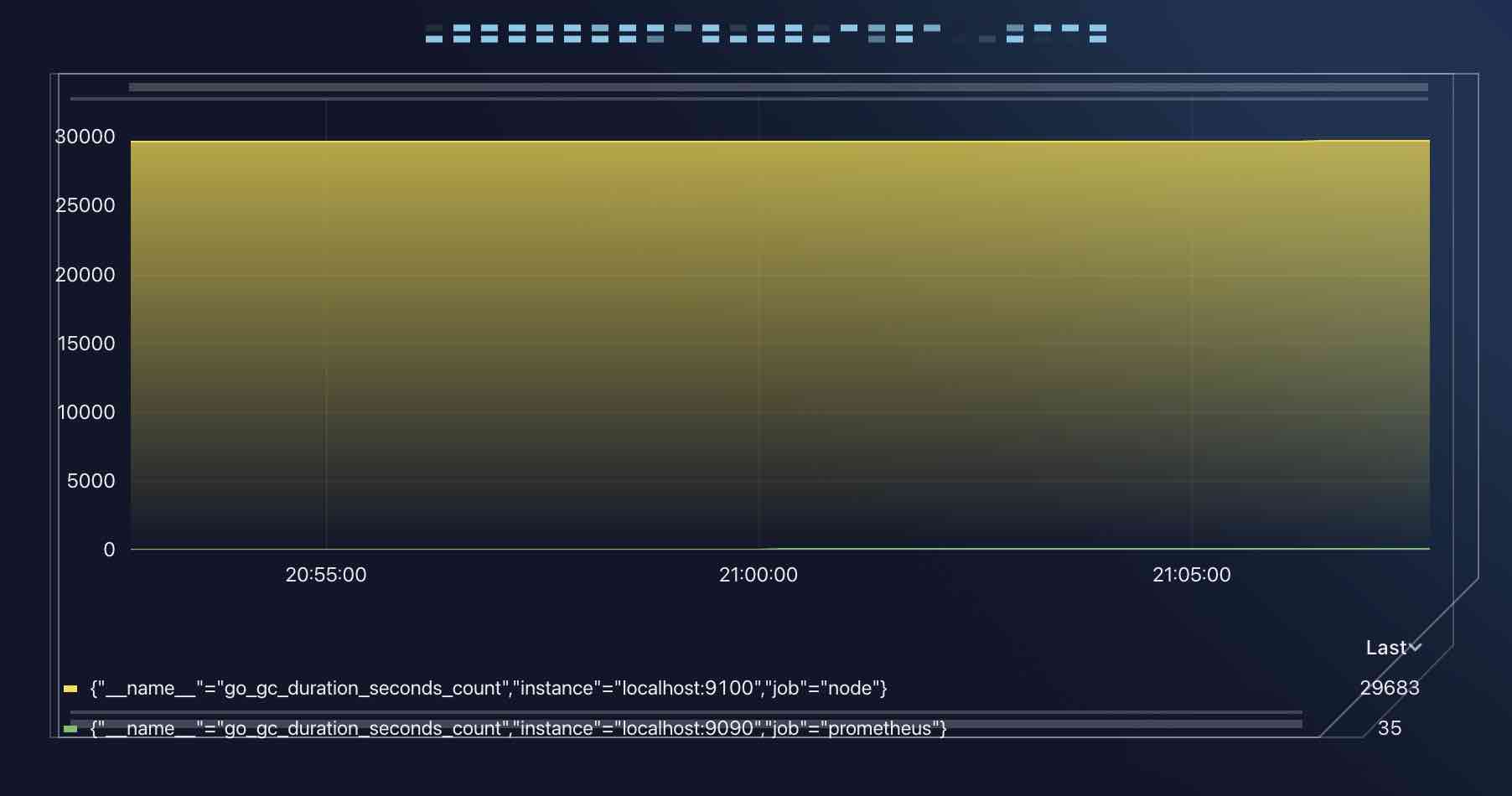
等等,看上去这个图表的边框和装饰都不适合告警,有些过于花里胡哨了,必须换!
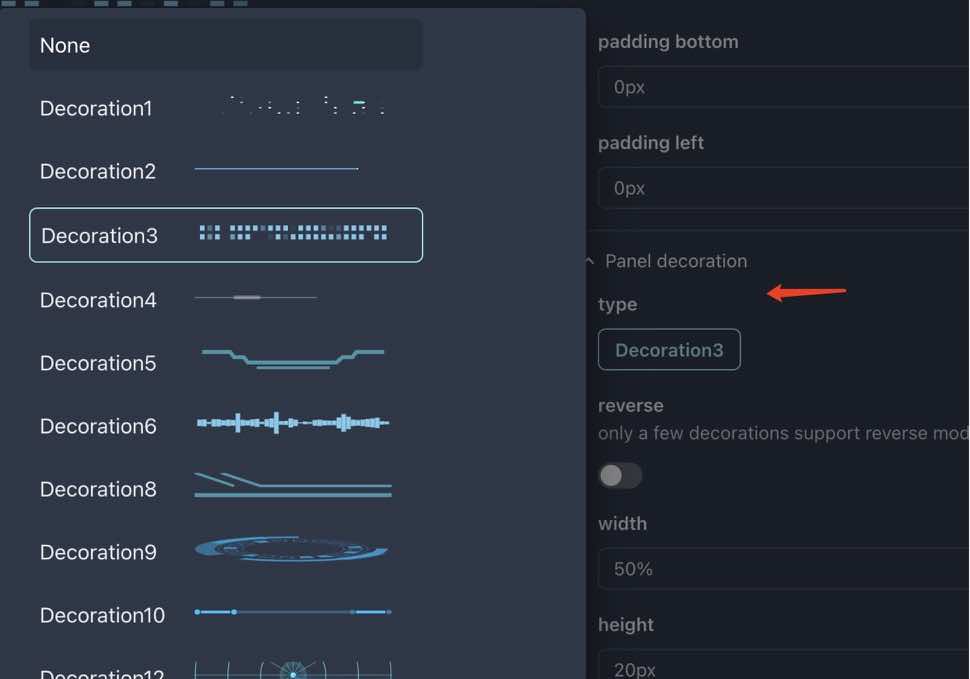
修改图表的边框和装饰
- 打开图表的编辑面板,在右边选择
样式标签页 - 点击下面的按钮选择一个新的边框
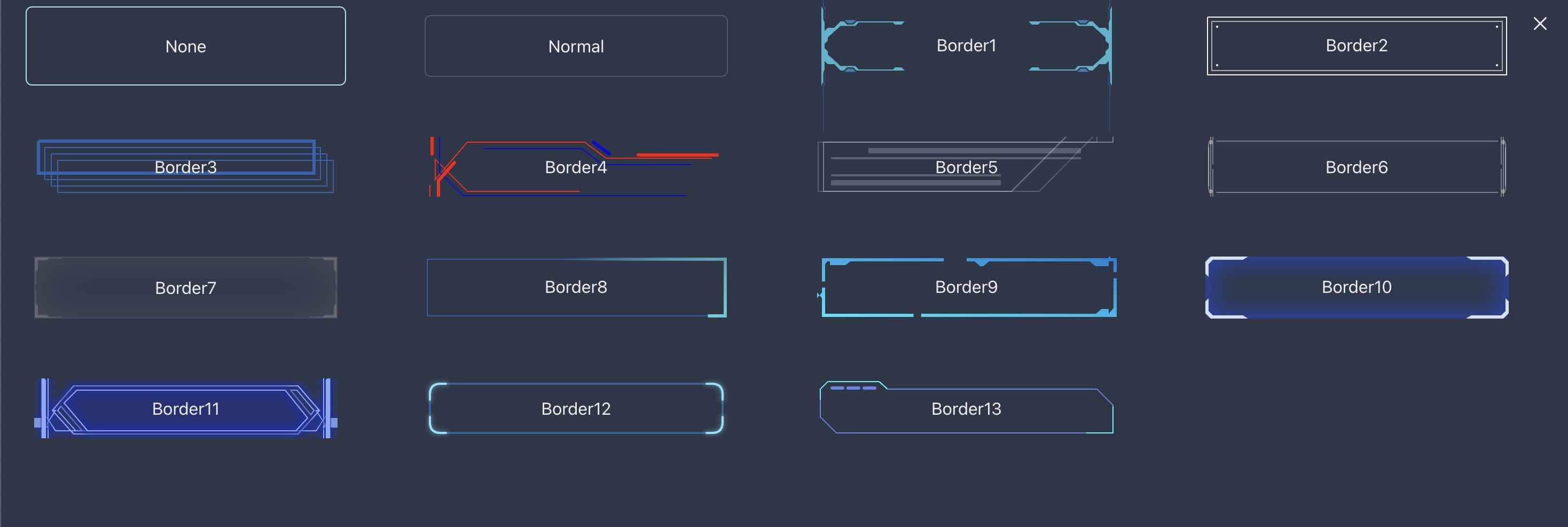
- 为了简洁,直接选择无边框:
None
- 找到
图表装饰设置,也将其设置为None
在设置后,我们的图表变成了这样:
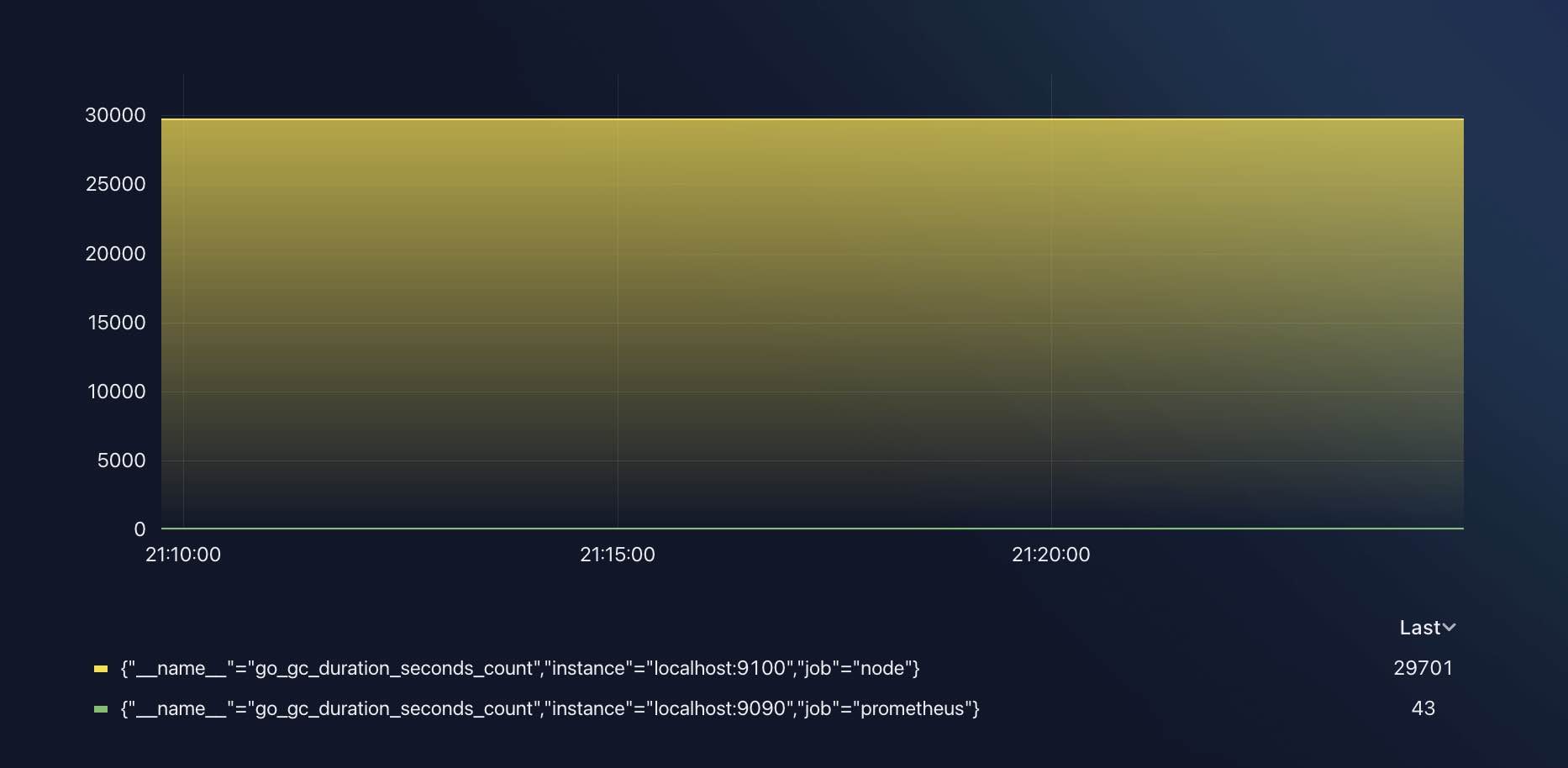
看上去干净多了,没有边框和装饰,只有一个纯粹的 Graph 图表。
开启告警关联
现在,我们已经有了一个 Graph 图表,接下来就是将告警关联到它上面。
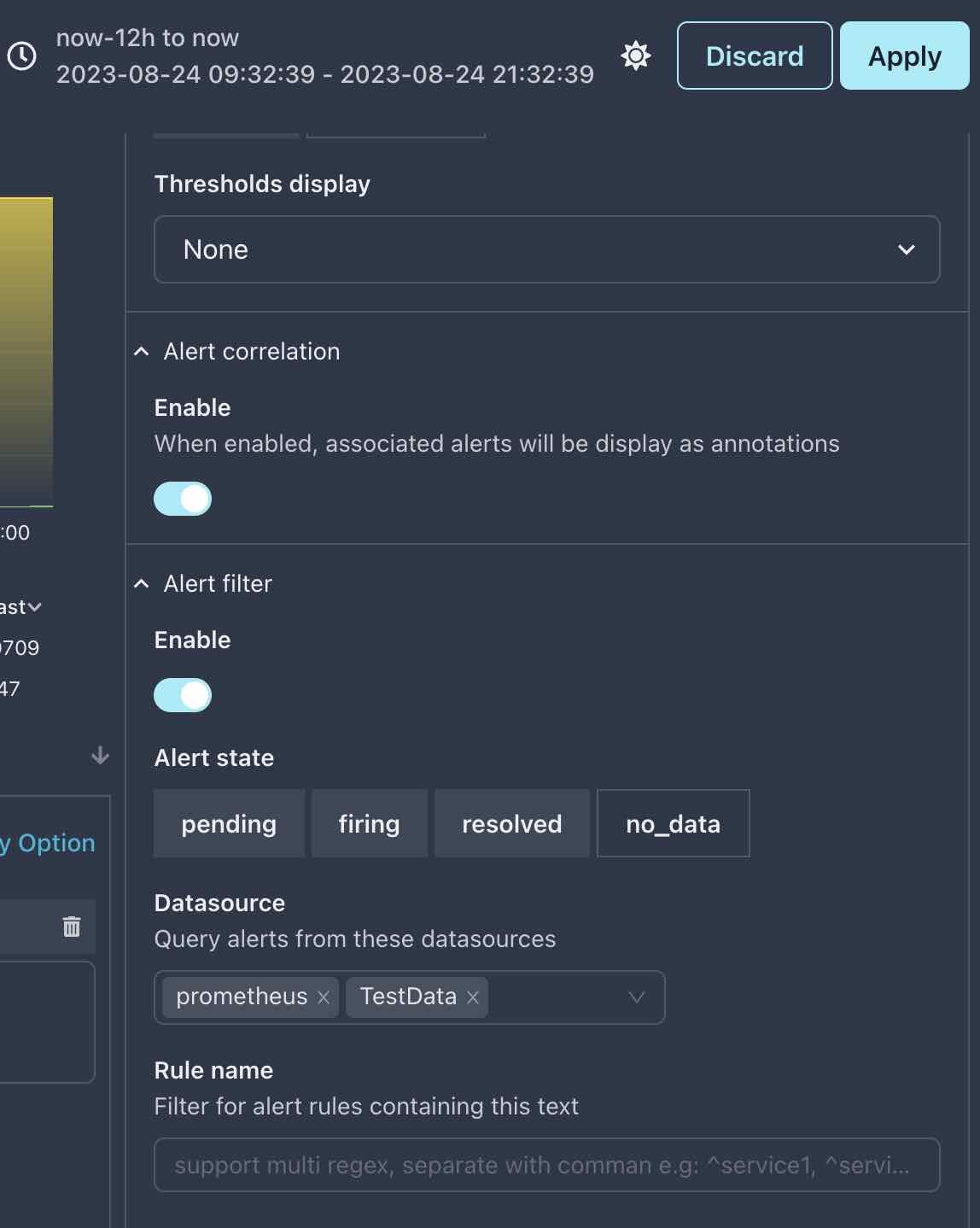
在图表编辑面板的 图表 标签页下,找到 告警关联 设置:
- 开启关联
- 选择
prometheus数据源, 如果实在没有告警数据,也可以选择TestData - 设置
告警状态过滤器,选择Pending,Firing和Resolved, 如果啥都不选,那么将没有告警被展示 - 也许你需要将时间范围设置到更宽广的范围,例如
now-12h to now
如果一切正常,那你将看到如下的 Graph 图表:
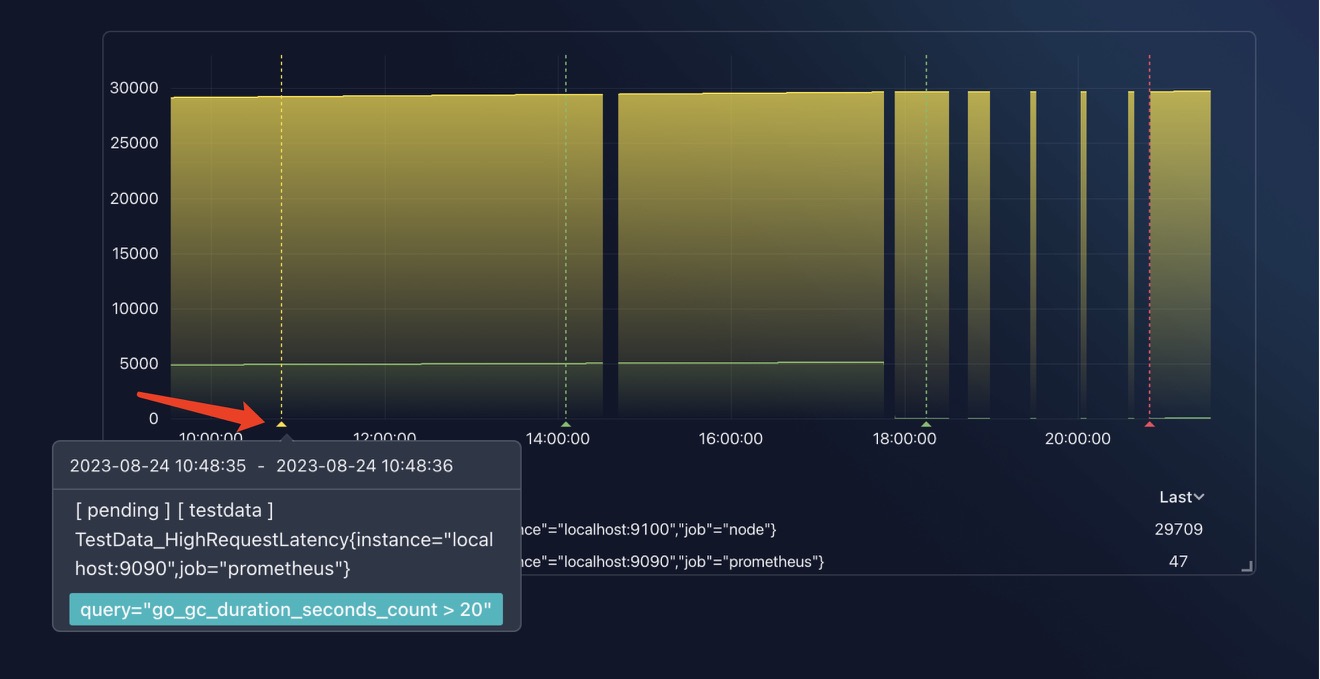
看图表上的标记了吗?将鼠标悬停在箭头指向的标记上,你将看到告警信息的弹出框。
查看告警详情
Graph 图表上的告警标记一般用于快速最近的告警总体状况,如果你想要查看更多关于告警的信息,可以这么做:
- 打开 Graph 图表的编辑面板
- 在左下方选择
告警标签页
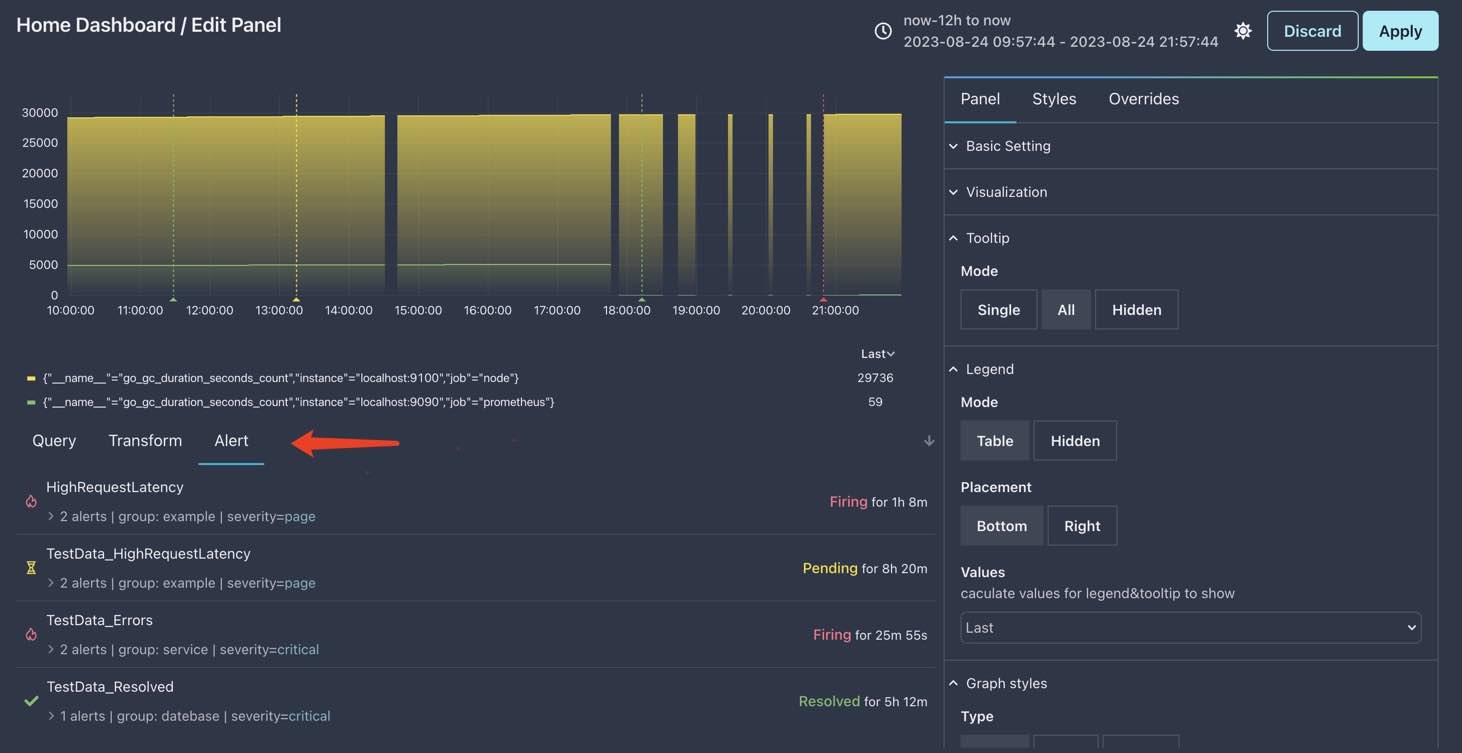
这里的数据跟 /alert 页面很像,但是在这里,你可以看同时看到告警列表和被标记的 Graph 图表。
事实上,你可以定制
/alert页面,用两个图表来实现同样的效果:一个 Graph 展示告警标记,另一个 Alert 展示告警列表